To showcase the performance of diseasystore on different
database backends, we include this vignette that summarises a simple
benchmark: A sample dataset is created based on the
datasets::mtcars dataset. This data is repeated 1000 times
and given a unique ID (the row number of the data):
benchmark_data
#> # A tibble: 32,000 × 13
#> row_id car mpg cyl disp hp drat wt qsec vs am gear
#> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 Mazda RX4… 21 6 160 110 3.9 2.62 16.5 0 1 4
#> 2 2 Mazda RX4… 21 6 160 110 3.9 2.88 17.0 0 1 4
#> 3 3 Datsun 71… 22.8 4 108 93 3.85 2.32 18.6 1 1 4
#> 4 4 Hornet 4 … 21.4 6 258 110 3.08 3.22 19.4 1 0 3
#> 5 5 Hornet Sp… 18.7 8 360 175 3.15 3.44 17.0 0 0 3
#> 6 6 Valiant 6 18.1 6 225 105 2.76 3.46 20.2 1 0 3
#> 7 7 Duster 36… 14.3 8 360 245 3.21 3.57 15.8 0 0 3
#> 8 8 Merc 240D… 24.4 4 147. 62 3.69 3.19 20 1 0 4
#> 9 9 Merc 230 9 22.8 4 141. 95 3.92 3.15 22.9 1 0 4
#> 10 10 Merc 280 … 19.2 6 168. 123 3.92 3.44 18.3 1 0 4
#> # ℹ 31,990 more rows
#> # ℹ 1 more variable: carb <dbl>A simple diseasystore is built around this data, with
two ?FeatureHandlers, one each for the cyl and
vs variables.
DiseasystoreMtcars <- R6::R6Class(
classname = "DiseasystoreBase",
inherit = DiseasystoreBase,
private = list(
.ds_map = list("n_cyl" = "mtcars_cyl", "vs" = "mtcars_vs"),
mtcars_cyl = FeatureHandler$new(
compute = function(start_date, end_date, slice_ts, source_conn) {
out <- benchmark_data |>
dplyr::transmute(
"key_car" = .data$car, "n_cyl" = .data$cyl,
"valid_from" = Sys.Date() - lubridate::days(2 * .data$row_id - 1),
"valid_until" = .data$valid_from + lubridate::days(2)
)
return(out)
},
key_join = key_join_sum
),
mtcars_vs = FeatureHandler$new(
compute = function(start_date, end_date, slice_ts, source_conn) {
out <- benchmark_data |>
dplyr::transmute(
"key_car" = .data$car, .data$vs,
"valid_from" = Sys.Date() - lubridate::days(2 * .data$row_id),
"valid_until" = .data$valid_from + lubridate::days(2)
)
return(out)
},
key_join = key_join_sum
)
)
)Two separate benchmark functions are created. The first benchmarking
function tests the computation time of
$get_feature() by computing first the
n_cyl feature then computing the vs feature,
before finally deleting the computations from the database.
The second benchmarking function tests the computation time of
$key_join_features() by joining the
vs feature to the n_cyl observation. Note that
the n_cyl and vs are re-computed before the
benchmarks are started and are not deleted by the benchmarking function
as was the case for the benchmark of
$get_feature(). In addition, we only use
the first 100 rows of the benchmark_data for this test to
reduce computation time.
The performance of these benchmark functions are timed with the
{{microbenchmark}} package using 10 replicates. All
benchmarks are run on the same machine.
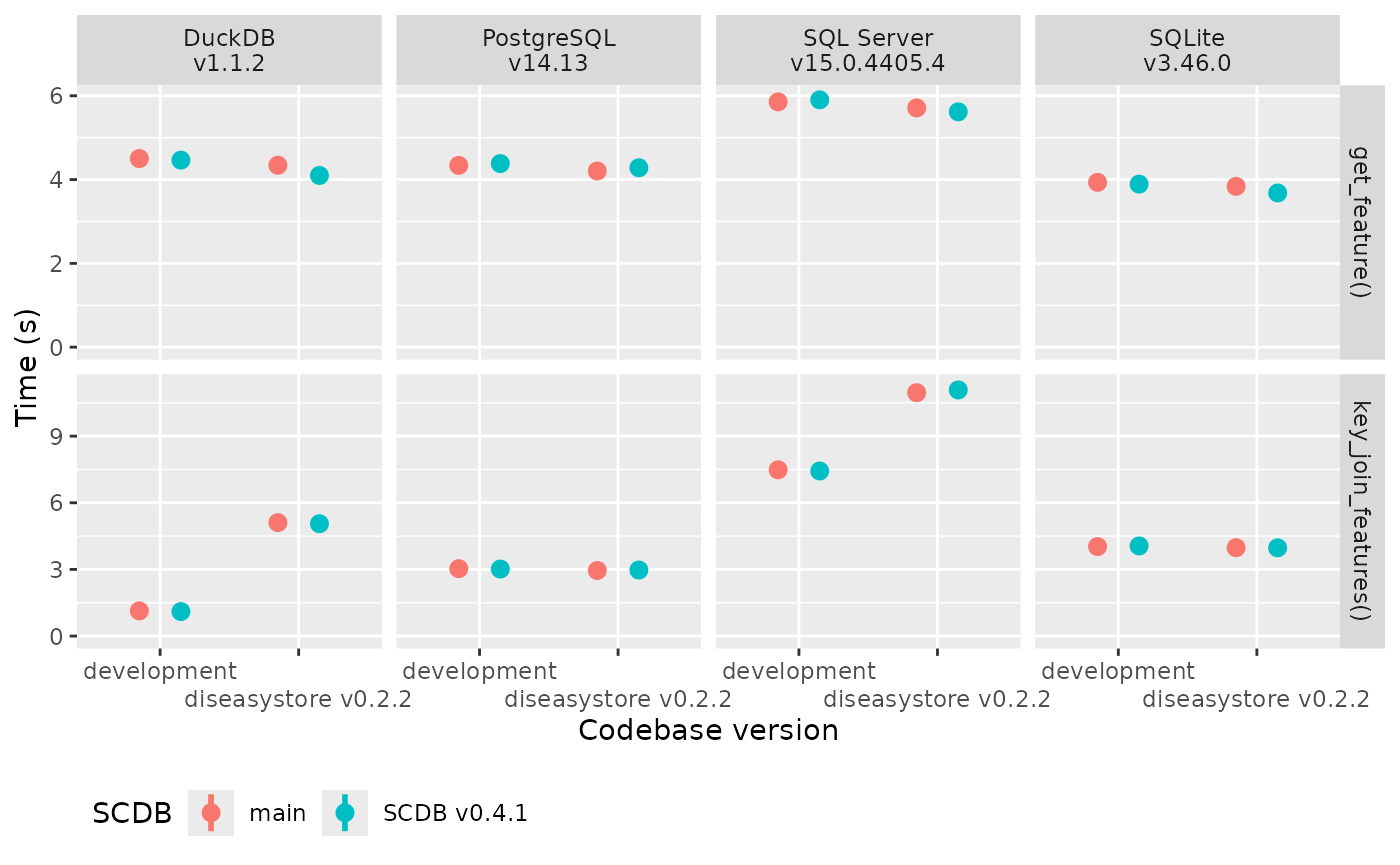
The results of the benchmark are shown graphically below (mean and
standard deviation), where we compare the current development version of
diseasystore with the current CRAN version. In addition, we
run the benchmarks with the current development version of
SCDB versus the current CRAN version since
SCDB is used internally in diseasystore.