Introduction
This vignette is a companion to the implementation of the SEIR ode
model ?DiseasyModelOdeSeir.
As the name suggests, this model is a SEIR-like ordinary differential equation (ODE) model. Furthermore, the model is designed as flexible as possible to allow for a wide range of different model configurations. Meaning that the number of consecutive exposed, infected, and recovered states can be set arbitrarily, as well as the number of demographic groups (e.g. age groups or sex) and the number of variants.
Due to the flexibility of the model, the implementation is somewhat complex, which is why we include this vignette outlining the mathematical implementation of the model and connect it to the code.
Opening consideration
The design of the SEIR model is meant to be “standard” in the sense that it, in general, follows the structure and design of SEIR models in the community.
For clarity, we here describe the considerations needed to design the model.
Indexes and accents
To begin, here we define a fixed meaning to the different indices and accents used in the vignette:
| Symbol | Description |
|---|---|
| Exposed states | |
| Infected states | |
| Recovered states | |
| Demographic groups | |
| Variants | |
| Non-normalised quantity |
Where upper case letters denote the number of such elements and lower case letters denote a specific element.
The model structure
The SEIR model we are building is a compartmental model with an (near) arbitrary number of exposed, infected, and recovered compartments. The model also supports multiple demographic groups and multiple variants.
We divide the model into different “tracks” with each track implementing the disease progression for a group of individuals. That is, if we have demographic groups and variants, we have tracks which each start with the first exposed state (or the first infected state if no exposed states are included in the model). As the infection progresses within each individual, they are moved down the track through infection and eventually into recovery.
Schematically, the model can be represented as in the figure below:
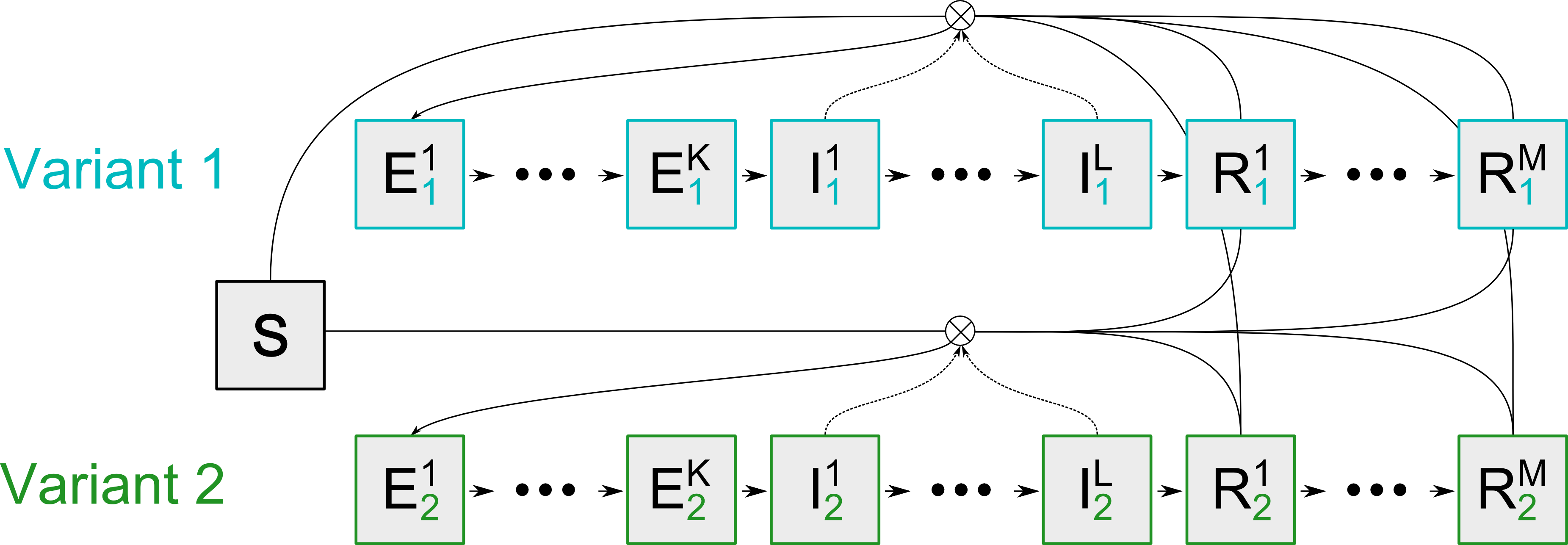
SEIR model overview for a two variant model
This figure shows the disease progression for two variant tracks for a single demographic group. The arrows in the figure indicates the infections in the model within these tracks.
State vector
Each “track” of infection is placed in a sequence in the state vector, , and increments first in demographic groups then in variants.
Finally, the susceptible states are placed at the end of the state vector1.
NOTE: State vector uses normalised (unit) populations.
Notice that the state vector elements are indexed by state-type, state-index, demography-index and variant-index:
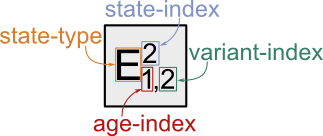
Index guide for the state vector
Contact matrix
If we define a risk of infection per contact, , the differential equation governing the infectious in the simple SIR model can then be expressed as:
To compute the number of infectious contacts we need the number of contacts between infected individuals of any demographic group and individuals in the ’th demographic group. If is the (symmetric) number of contacts between demographic group and demographic group , then is the number of infectious contacts from to (infected individual of demographic group times mean number of contacts to demographic group with each contact carrying a risk of infection ).
The probability that a contact is susceptible is simply its proportion relative to the demographic group leading to:
Collecting terms:
Then, dividing through by the total population size yields:
Then expanding by and expressing in terms of .
and finally expressing in terms of normalised quantities
Notice that we obtain terms of the form:
The implementation of the right-hand side function
With the opening considerations in mind, we can now describe the implementation of the model. Below, we now link the implementation with the underlying mathematical descriptions of the model.
The ?DiseasyModelOdeSeir model implements the
DiseasyModelOdeSeir$rhs method which computes the rates
needed for the ODE solver. The evaluation of this right-hand side
function uses a few intermediate variables which are described
below.
The infected matrix
In the computation of the right-hand side of the ODE, we have a
helper matrix
stored as infected in the implementation.
This matrix is a matrix with elements
That is, the element contains the sum of all infected compartments for the track associated with demographic group and variant .
The infected_contact_rate matrix
During the right-hand side computation, we also have a helper matrix
infected_contact_rate which is
That is, the element contains the rate of contact for demographic group with persons infected with variant across all demographic groups.
The infection_rate matrix
Continuing the computation of the right-hand side, we have the
infection_rate matrix
()
which is the infected_contact_rate
()
adjusted for additional risk factors.
- : Multiplicative effect of season
- : Relative infectiousness of variant
- : Overall infection rate scaling factor
Where is the Hadamard product (element-wise multiplication), and is the matrix:
NOTE: In the code,
private$indexed_variant_infection_risk is
in vector form.
The infection_matrix
For the final computation of infections of the right-hand side, we
construct the matrix infection_matrix
().
Since only and compartments are susceptible to infection, we need only to consider the states to compute the new infections in the model.
The new infection_matrix therefore does not need to
contain the
exposed states and the
infected states, but only the
recovered states and the
susceptible states.
We are therefore interested in the reduced state vector whose elements are the and elements of the full state vector .
We now create an intermediate matrix
by expanding the infection_rate matrix
()
to a
matrix by repeating the rows of the infection_rate matrix.
This repeating is done by matching the demographic group of the
infection_rate matrix to the demographic group of the
reduced state vector. Each element,
,
in the state vector,
has a corresponding demographic group which we can write as
.
The intermediate matrix , has a row for all states in or compartments and column for each variant. The form is as follows:
We now have a matrix, whose elements are the infection rate for each variant matched to the and elements of the state vector.
In this space, we can now account for:
- The state specific infection risks (i.e. the reduced risk from being infected previously / vaccinated)
- The effect of cross-immunity between the variants
That is, we need to construct the matrix that accounts for the waning of immunity () and the cross-immunity factors (Variant infecting a person with immunity for variant ).
All together, this is implemented via the immunity matrix
(immunity_matrix)
which is
matrix on the form:
Where is a ones vector of length .
In , the sub-matrices of the form:
are matrices with repeated sub-matrices. That is, is a vector of length which is repeated for each demographic group, to form the matrix.
In total, the matrix accounts for the cross-variant reductions of immunity ().
Finally, we can combine everything to the flow matrix:
Where is repeats of the and elements of the state vector .
This matrix contains, for each and element in the state vector, a row consisting of per-variant infectious contacts between the corresponding compartment and the infected population in the model. These elements account for every risk modifying mechanism included in the model.
The row sums of this matrix is then equal to the loss from the compartment due to infectious contacts. The sums by variant/demographic group combination can also be extracted from the matrix to form the in-flow of new infections to the compartments.
Generator matrix
Beyond implementing the right-hand side of the ODE, we also implement the generator matrix for the model.
The generator matrix, , is a matrix containing the dynamics of the and states under the assumption of static and states.
Formally, the generator matrix is the linearisation:
The matrix can be decomposed into two contributions:
- The transition matrix, , which is a bi-diagonal matrix containing the flow rates between sequential compartments
- The transmission matrix, which contains the flows stemming from infections.
The transition matrix is block-diagonal and has the form (here for and and :
Notice that the off-diagonal has zero-elements where the (reduced) state vector changes demographic groups ().
The form of the transmission matrix is more difficult to write up.
We lump risk modifying factors such as the effect of season and overall infection rate into a single factor .
Some examples:
Two demographic groups, single variant
As long as we have only a single variant, cross immunity can be ignored and we can lump the effect of the balance between to into .
For and , the transmission matrix is:
For and , the transmission matrix is:
Single demographic group, double variant
With only one demographic group, the contact matrix is the scalar .
With two variants, we need to also account for the relative infectivity of the variants .
Then, for and , the transmission matrix is:
Where the change between variants is demarcated visually by the vertical and horizontal lines. We now have the additional factor which explicitly accounts for the balance of and states and the cross-immunity between the variants:
That is, we have the unmodified contribution from the states, and the contribution from all states while accounting for waning of immunity () and cross-immunity ().
This factor is analogous to a “cross-section” of infection encounter, i.e. a factor that accounts for the probability that a contact between an infectious and non-infected person is an infectious contact.
Then, for and , the transmission matrix is:
Notes on optimisations of the right-hand side function
It is important that the implementation is somewhat optimised for the simulations to run in a reasonable time frame. To that end, we here show micro-benchmarks of different implementations of the same steps with the time consumption as output, to highlight why a given implementation was chosen.
These benchmarks assume a simple SEIR model with only three demographic groups and one variant.
“infected” sum computation
## Step 1, determine the number of infected by demographic group and variant
i_state_indices <- list(2, 5, 8)
state_vector <- rep(0, 9)
# Benchmark possible approaches
microbenchmark::microbenchmark( # Microseconds
"purrr::map_dbl" = purrr::map_dbl(
i_state_indices,
\(indices) sum(state_vector[indices])
),
"sapply" = sapply(
i_state_indices,
\(indices) sum(state_vector[indices])
),
"sapply - USE.NAMES" = sapply(
i_state_indices,
\(indices) sum(state_vector[indices]),
USE.NAMES = FALSE
),
"vapply" = vapply(
i_state_indices,
\(indices) sum(state_vector[indices]),
FUN.VALUE = numeric(1),
USE.NAMES = FALSE
),
check = "equal", times = 1000L
)
#> Unit: microseconds
#> expr min lq mean median uq max neval
#> purrr::map_dbl 24.897 27.2910 29.408672 28.7085 29.856 109.364 1000
#> sapply 12.814 13.2850 16.366648 13.6805 14.657 2194.899 1000
#> sapply - USE.NAMES 12.804 13.3195 14.499338 13.7605 14.657 39.724 1000
#> vapply 4.899 5.3605 5.722089 5.5910 5.811 25.878 1000Note, that the best performing function in this case is
vapply().