library(diseasy)
#> Loading required package: diseasystore
#>
#> Attaching package: 'diseasy'
#> The following object is masked from 'package:diseasystore':
#>
#> diseasyoptionIntroduction
One of the model families in diseasy is the family of
Ordinary Differential Equation (ODE) models. This family of models is
presently represented only by the ?DiseasyModelOdeSeir, a
model template that implements SEIR (Susceptible, Exposed, Infected,
Recovered) ODE models according to user specification. This template
allows for any number of
,
or
states in the model and interfaces with the ?DiseasySeason,
?DiseasyActivity, ?DiseasyVariant and
?DiseasyImmunity modules for scenario definitions.
The workflow for creating a specific
?DiseasyModelOdeSeir model would roughly follow these
steps:
-
Defining the model scenario. The first step to
using most models in
diseasyis to define the scenario. That is, to configure the functional modules that the model templates takes as argument (e.g.?DiseasyActivity). These steps provide the model template with information about the population, the activity, variants to include etc. -
Choosing the model configuration. The model
template may have some configurability that you control. In the case of
?DiseasyModelOdeSeirfor example, you must choose the number of consecutive , and states in the model. - Mapping to observables. The ODE family of models is in some ways bespoke in the sense that the user needs to provide a mapping from and to real-world observables.
We distinguish between two mappings: First, observed real-world data, such as positive tests or hospitalisations, is used to estimate the “true” incidence of infections. Secondly, the modelled incidence is then mapped back to the observable quantities of interest.
The model must have an estimate of the disease incidence to be initialised. If no reverse mappings are given, the model can only provide predictions for the true incidence and true number of infected.
These steps are outlined in individual sections below where we work through defining a model in a specific example. Note that this example is contrived in the sense that the data we use in this example have been generated with this exact model template and we therefore can match the observations near-perfectly.
Example data
The data we will use this example is provided by
?DiseasystoreSeirExample which represents data in a Danish
context.
We first create an observables module to interface with this data:
# Configure a observables module with the example data and database
observables <- DiseasyObservables$new(
diseasystore = DiseasystoreSeirExample,
conn = DBI::dbConnect(RSQLite::SQLite())
)The data is stratified by age and covers a single infection wave. It contains three observables of interest for our example:
- n_infected: The true number of infected in the data.
- n_positive: The observed subset of infected (65% of true infected are observed but fewer are observed during the weekend).
- n_admissions: The number of new hospital admissions due to infections (risk of hospitalisation dependent on age group).
When running the models, we should also define at what point in time
they should provide predictions for. This is done by setting the
last_queryable_date in the observables module:
last_queryable_date <- observables$ds$min_start_date + 45Lets first look at the data we have available:
observables$get_observation(
observable = "n_infected",
stratification = rlang::quos(age_group),
start_date = observables$ds$min_start_date,
end_date = observables$ds$max_end_date
) |>
ggplot2::ggplot(ggplot2::aes(x = date, y = n_infected)) +
ggplot2::geom_vline(
xintercept = last_queryable_date,
color = "black",
linetype = "dashed"
) +
ggplot2::geom_point(color = "deepskyblue3") +
ggplot2::labs(title = "True number of infected") +
ggplot2::facet_grid(~ age_group)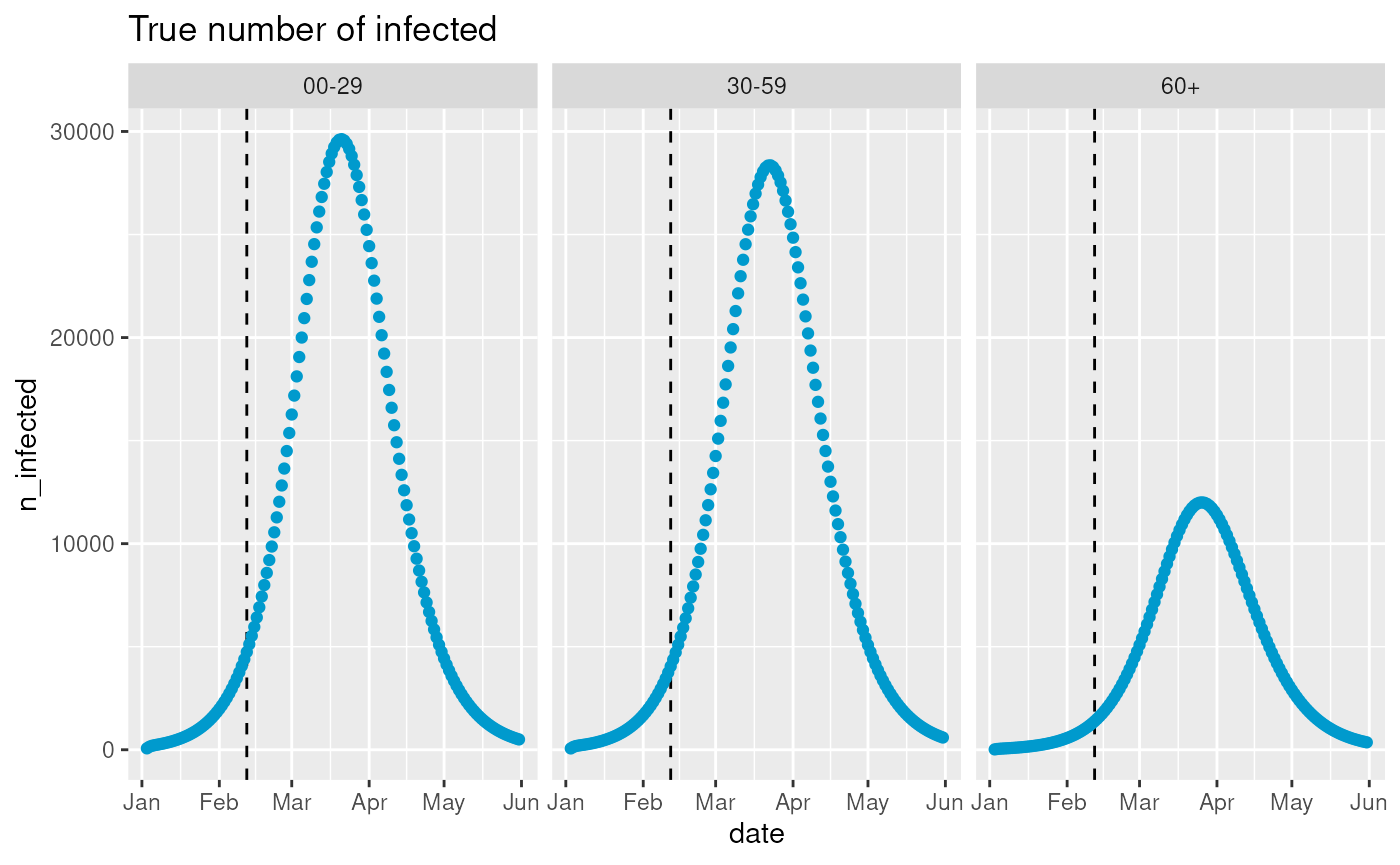
observables$get_observation(
observable = "n_positive",
stratification = rlang::quos(age_group),
start_date = observables$ds$min_start_date,
end_date = observables$ds$max_end_date
) |>
ggplot2::ggplot(ggplot2::aes(x = date, y = n_positive)) +
ggplot2::geom_vline(
xintercept = last_queryable_date,
color = "black",
linetype = "dashed"
) +
ggplot2::geom_point(color = "seagreen") +
ggplot2::labs(title = "Observed number of positive cases") +
ggplot2::facet_grid(~ age_group)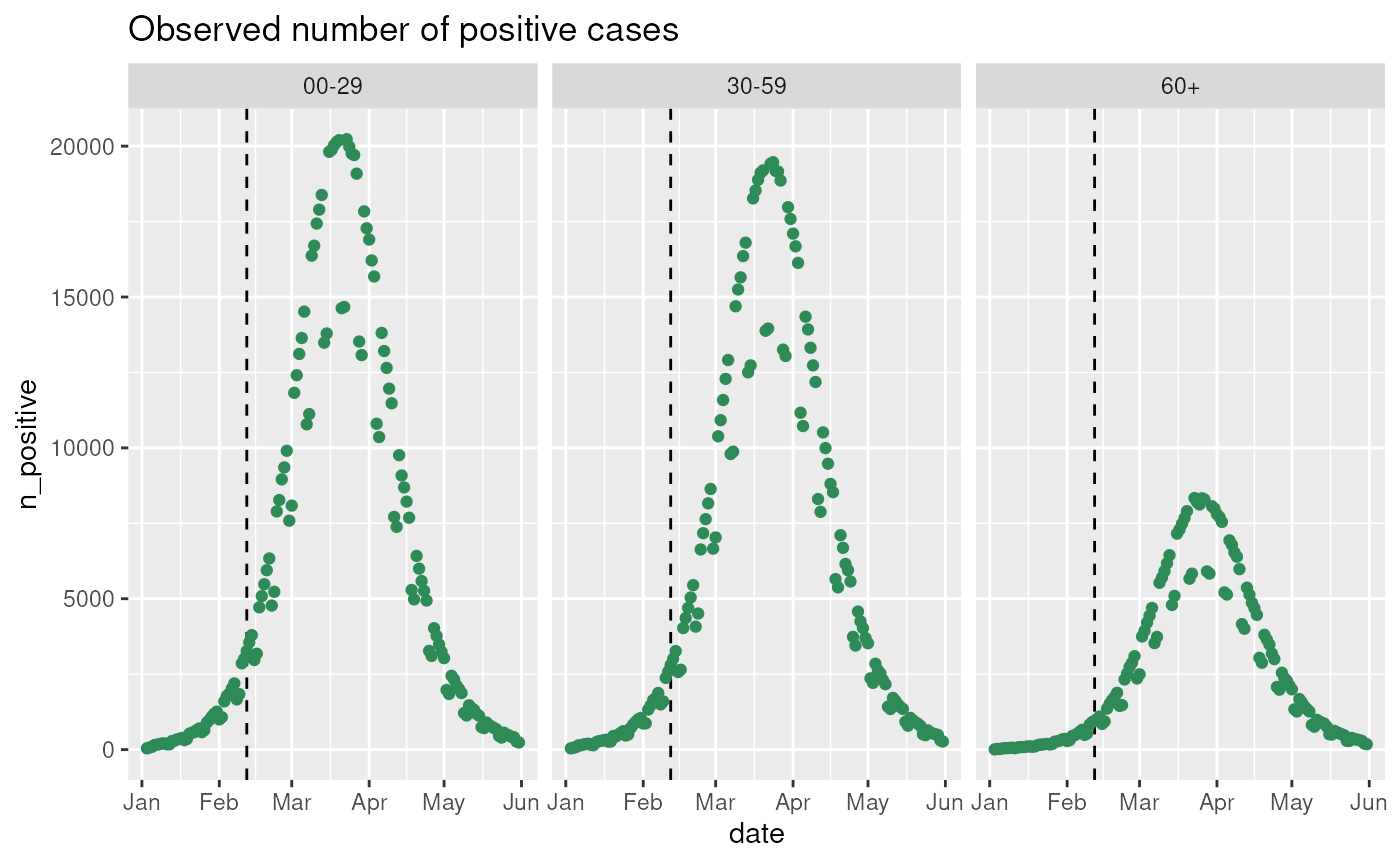
observables$get_observation(
observable = "n_admission",
stratification = rlang::quos(age_group),
start_date = observables$ds$min_start_date,
end_date = observables$ds$max_end_date
) |>
ggplot2::ggplot(ggplot2::aes(x = date, y = n_admission)) +
ggplot2::geom_vline(
xintercept = last_queryable_date,
color = "black",
linetype = "dashed"
) +
ggplot2::geom_point(color = "violetred3") +
ggplot2::labs(title = "Number of admissions") +
ggplot2::facet_grid(~ age_group)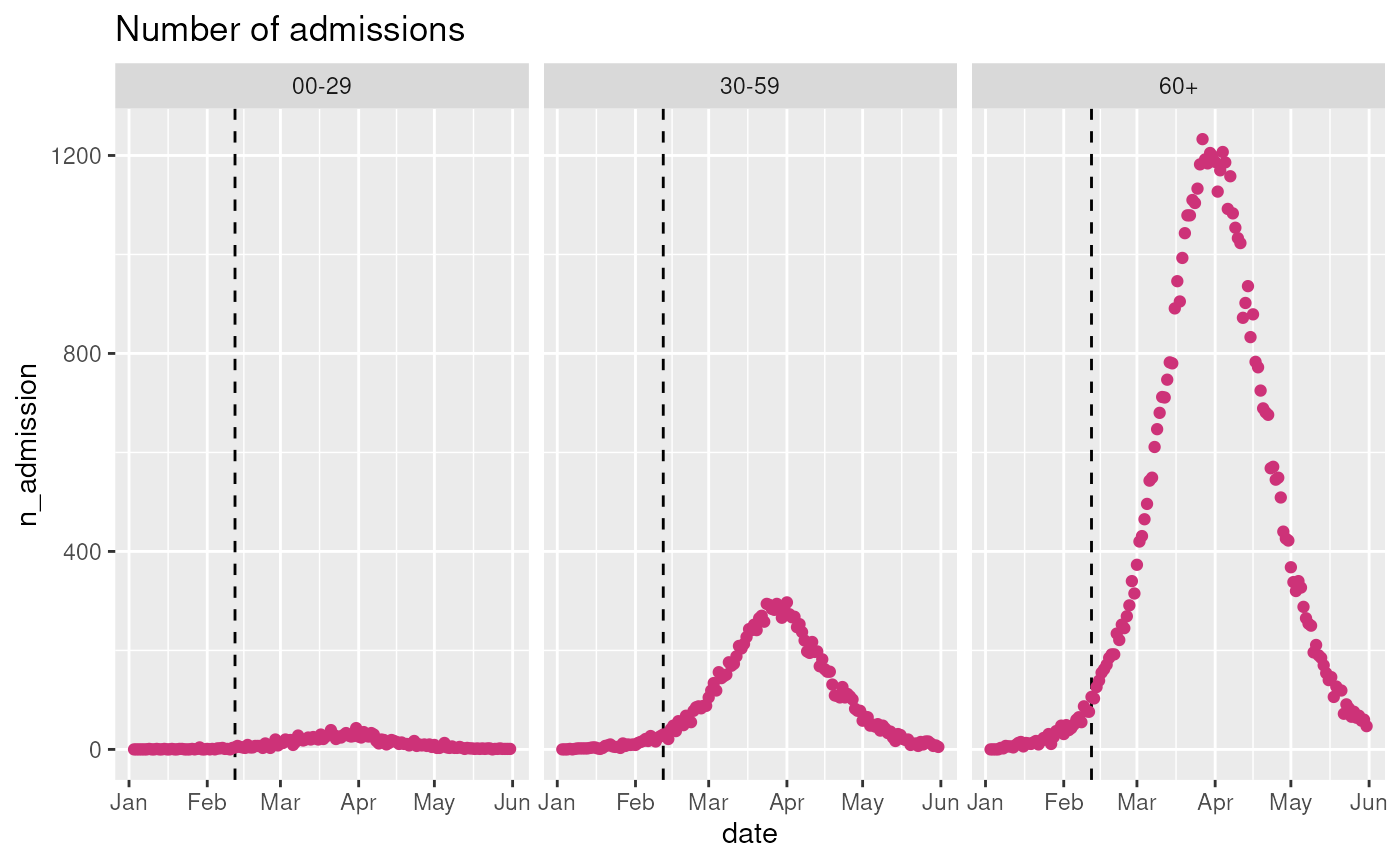
Defining the scenario
The first step to creating a ?DiseasyModelOdeSeir model
is to define the model scenario. In this case, as we stated above, we
can exactly match the model scenario to the data since the data was
created using the same class of models.
First we define the population to include in the model via the
?DiseasyPopulation module, and then we define the activity
scenario via the ?DiseasyActivity module, before finally
defining the seasonality scenario via the ?DiseasySeason
module.
Model population
In this example scenario, we use a simple three age-group stratification of the population in the model.
# Split the model population into three age groups
population <- DiseasyPopulation$new()
population$stratify_age(age_cuts_lower = c(0, 30, 60))Activity scenario
This scenario describes the changes in activity in the society
(e.g. restrictions). To see more on how to configure this module, see
vignette("diseasy-activity").
# Configure an activity module using Danish population and contact information.
activity <- DiseasyActivity$new()
activity$set_contact_basis(contact_basis = contact_basis_nordic$DK)
activity$set_activity_units(dk_activity_units)
# The level of activity is fixed to the "baseline" level throughout the simulation.
activity$change_activity(date = as.Date("2020-01-01"), opening = "baseline")Seasonality scenario
This particular scenario also includes simple seasonality and waning immunity:
# Waning immunity scenario
immunity <- DiseasyImmunity$new()
immunity$set_exponential_waning(time_scale = 180)
#> $infection
#> function (t)
#> exp(-t/time_scale)
#> <environment: 0x5648db61d5b8>
#> attr(,"name")
#> [1] "exponential_waning"
#> attr(,"dots")
#> attr(,"dots")$time_scale
#> [1] 180
# Season scenario
season <- DiseasySeason$new()
season$set_reference_date(as.Date("2020-01-20"))
season$use_cosine_season()Choosing the model configuration
The ?DiseasyModelOdeSeir model template has a number of
hyperparameters and parameters that should be configured for the model
to run.
The hyperparameters are:
- compartment_structure: A named vector specifying the number of consecutive , and states in the model.
The parameters are:
- disease_progression_rates: A named vector specifying the progression rates from to and from to (i.e. waiting times). The rates determine the expected time spent in each state).
- overall_infection_risk: A population-level scaling factor for transmission, controlling the overall risk of infection in the population.
Mapping observables to model and back
Being a SEIR model, the ?DiseasyModelOdeSeir model
template runs the dynamics of the infections in the population. These
dynamics are inferred from the incidence of the infections in the
population. These dynamics are not usually observed directly. Instead,
they must be inferred from one or more observed data sources, such as
positive tests or hospital admissions.
Mathematically, we map from the set of real-world observables to the incidence via the map : The model then produces a number of observations under the given configuration.
By default, the model will predict the evolution of the incidence1, , but other outputs can be configured (see further below).
To get predictions for other real-world observables, we must map from the incidence (or other output) to the observable of interest.
From the model incidence , we then map to the observable estimates via the maps :
Mapping from observables to incidence
For the model to be initialised, it needs an estimate of the
incidence in the population. This incidence is then used to infer the
dynamics of the disease in the population (See the article
SEIR-initialisation in the online documentation for more
information).
If an estimate of the incidence is not defined in the
diseasystore, or if you wish to provide your own estimate
from the observable, we can define a “synthetic observable” in the
DiseasyObservables module for the model to use.
In this example, the incidence is not defined in the
diseasystore and we therefore define a synthetic observable
for the incidence which maps from the number of positive cases to the
incidence. In many cases, testing data may not be reliable, and you may
want to infer the incidence from other sources such as waste water data
or admissions data.
# Map observables to incidence
observables$define_synthetic_observable(
name = "incidence",
mapping = \(n_positive, n_population) n_positive / (n_population * 0.65)
)Mapping from model incidence to observables
By default, the model can only return predictions for the “true”
number of infected (n_infected) and the incidence
(incidence) since these are the only observables “known” to
the model.
Any additional observables must be mapped from the incidence provided by the model, or other output must be defined to map from (see further below).
To convert from model outputs to real-world observables, we define a “map” and a “reduce” function:
The map function is passed to a
dplyr::group_map() call on a data.frame
grouped by the stratification. The function should be a two-argument
function where the first argument contains a data.frame
with columns n_infected and population
(i.e. the size of the group), and where the second argument contains the
group (as a data.frame). Note that the output of this
function should contain the groups provided in the second argument.
The reduce function is passed to a
dplyr::summarise() call on the output of the map. By
default, a simple sum is used which works for all counting data. If the
observable is not a count, the user must provide a custom reduce
function. For example, the incidence is a rate and to summarise a
weighted sum must be made.
In this example, we define maps from the incidence to the number of positive cases and the number of hospital admissions. These are both counting observables and the default reduce function can be used.
# Maps between the internal model incidence and observables
map_to_n_positive <- list(
"map" = \(.x, .y) {
dplyr::transmute(
.x,
.data$date,
"n_positive" = 0.65 * .x$n_infected
)
}
)
map_to_n_admission <- list(
"map" = \(.x, .y) {
# Risk per age group
risk_of_admission <- c("00-29" = 0.001, "30-59" = 0.01, "60+" = 0.1)
# Delay admissions by a fixed distribution
delay_distribution <- c(0, 0, 0.2, 0.3, 0.3, 0.1, 0.1) # Must sum = 1
data.frame(
"date" = as.vector(
outer(
X = .x$date,
Y = seq_along(delay_distribution) - 1,
FUN = "+"
)
),
"n_admission" = as.vector(
outer(
X = .x$n_infected * risk_of_admission[.y$age_group],
Y = delay_distribution,
FUN = "*"
)
)
)
}
)
# These maps are provided via a list to the model with the names of
# the elements denoting the observable being mapped to.
model_output_to_observable <- list(
"n_positive" = map_to_n_positive,
"n_admission" = map_to_n_admission
)Custom model output
The diseasy ODE model templates uses a generic system
for generating observables from the state_vector,
.
A observable can be configured to either derive from the full state
vector
or the infection matrix
(see the article SEIR-implementation in the online
documentation).
For example, if the user wants to configure an observable for the prevalence of the disease rather than the incidence, a observable summing across the states in the model can be used.
Alternatively, if the user wants to configure observables related to infections, such as hospitalisation, a observables summing across the infection matrix with age-specific risks of hospitalisation can be used.
In either case, the observable is configured by defining a vector of weights. For each of such vectors, a “surveillance” state is added to the state_vector which integrates the inner-product or depending on which element the observable is set to track.
In the former case, the surveillance states are derived from the state_vector whereas in the latter the observable is derived from the new infections occurring in the model.
In the case of the “n_infected” observable defined by default in the model, the weights are essentially a matrix with weights only for each state2 and the observable tracks the state_vector.
For example, in SEIR case () with two age-groups, the weights take the following form:
where is the rate of transition out of (i.e. the reciprocal of the time spent in state).
As stated above, the model always provides a prediction for the
“n_infected” observable but there are cases where other observables are
automatically configured by diseasy.
For example, when the model includes a ?DiseasyImmunity
module, observables are configured to track outcomes related to
immunity.
Here, waning target named “hospitalisation” or “death” in the immunity scenario are assigned their own observables which are derived from the infection matrix (Note that there is no difference in waning between variants included in the model).
In the SEIR3 case () with two age-groups, the weights take the following form:
In the SEIR2 case () with two age-groups and two variants, the weights take the following form:
Putting it all together
With all the configuration done above, we can now create our model instance.
model <- DiseasyModelOdeSeir$new(
# Scenario configuration
population = population,
activity = activity,
immunity = immunity,
season = season,
observables = observables,
parameters = list(
# Parameter and hyper-parameter configuration
"compartment_structure" = compartment_structure,
"overall_infection_risk" = overall_infection_risk,
"disease_progression_rates" = disease_progression_rates,
# Mapping to observables
"model_output_to_observable" = model_output_to_observable
)
)Predicting the incidence
From this point, we can easily get predictions for the individual observables.
model$get_results(
observable = "incidence",
prediction_length = 5
)
#> # A tibble: 5 × 4
#> date incidence realisation_id weight
#> <date> <dbl> <dbl> <dbl>
#> 1 2020-02-18 0.00199 1 1
#> 2 2020-02-19 0.00212 1 1
#> 3 2020-02-20 0.00227 1 1
#> 4 2020-02-21 0.00243 1 1
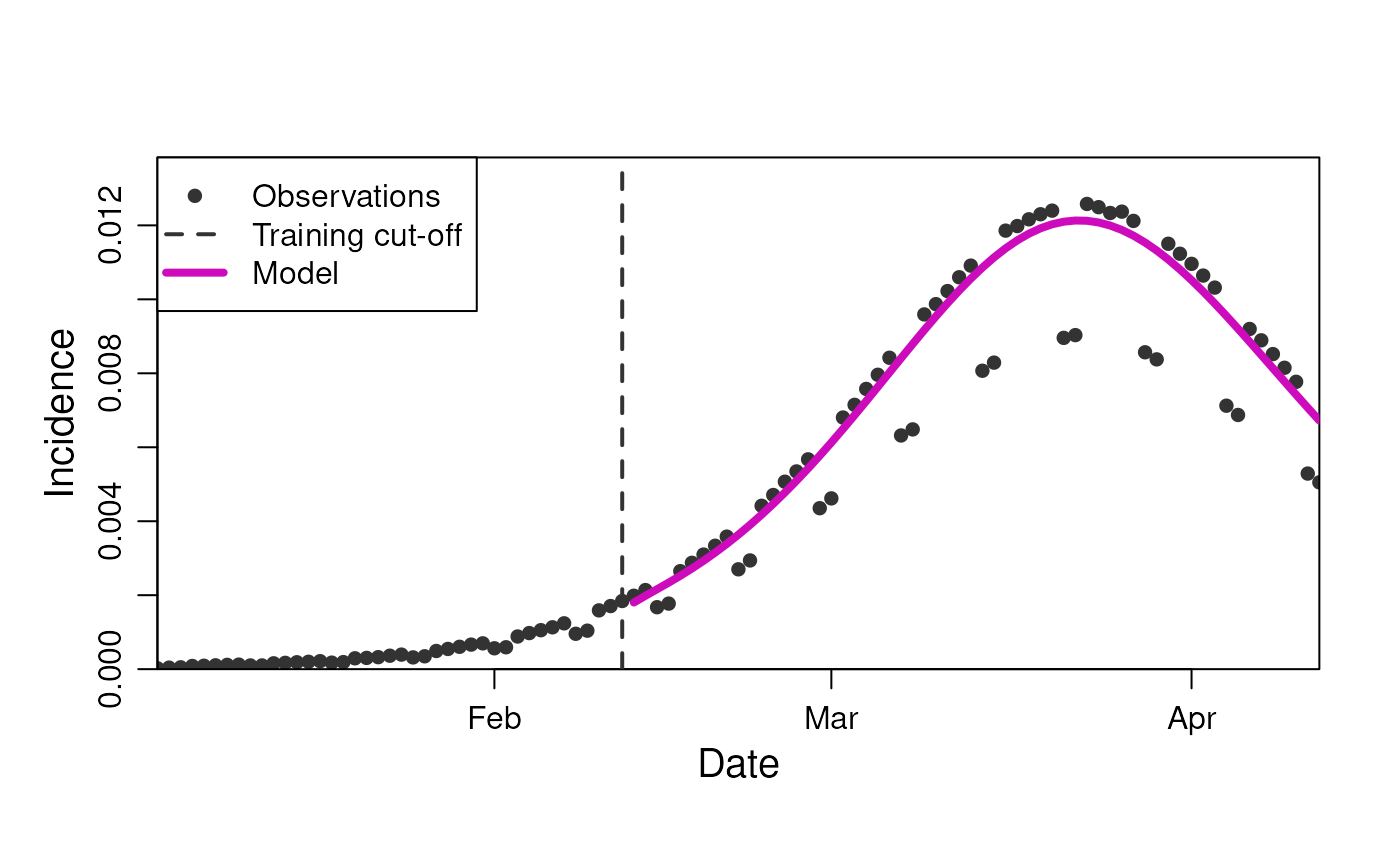
#> 5 2020-02-22 0.00261 1 1… and we can plot the predictions along with observations for the data
plot(
model,
observable = "incidence",
prediction_length = 60
)
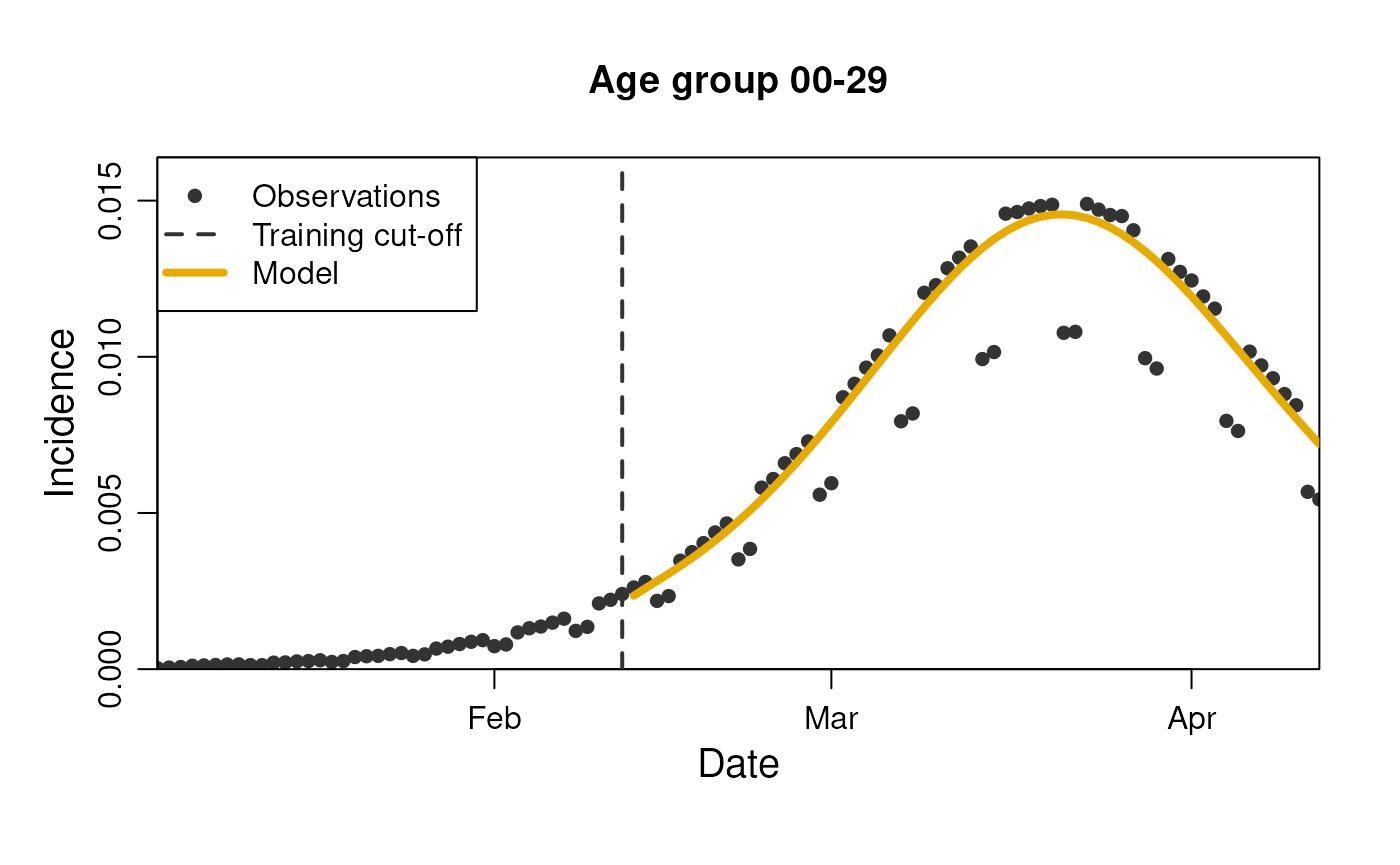
The results are easily stratified by the stratifications in the data
model$get_results(
observable = "incidence",
prediction_length = 3,
stratification = rlang::quos(age_group)
)
#> # A tibble: 9 × 5
#> date age_group incidence realisation_id weight
#> <date> <chr> <dbl> <dbl> <dbl>
#> 1 2020-02-18 00-29 0.00259 1 1
#> 2 2020-02-19 00-29 0.00275 1 1
#> 3 2020-02-20 00-29 0.00294 1 1
#> 4 2020-02-18 30-59 0.00207 1 1
#> 5 2020-02-19 30-59 0.00220 1 1
#> 6 2020-02-20 30-59 0.00236 1 1
#> 7 2020-02-18 60+ 0.00106 1 1
#> 8 2020-02-19 60+ 0.00113 1 1
#> 9 2020-02-20 60+ 0.00121 1 1… and we can see the plots for each strata.
plot(
model,
observable = "incidence",
prediction_length = 60,
stratification = rlang::quos(age_group)
)
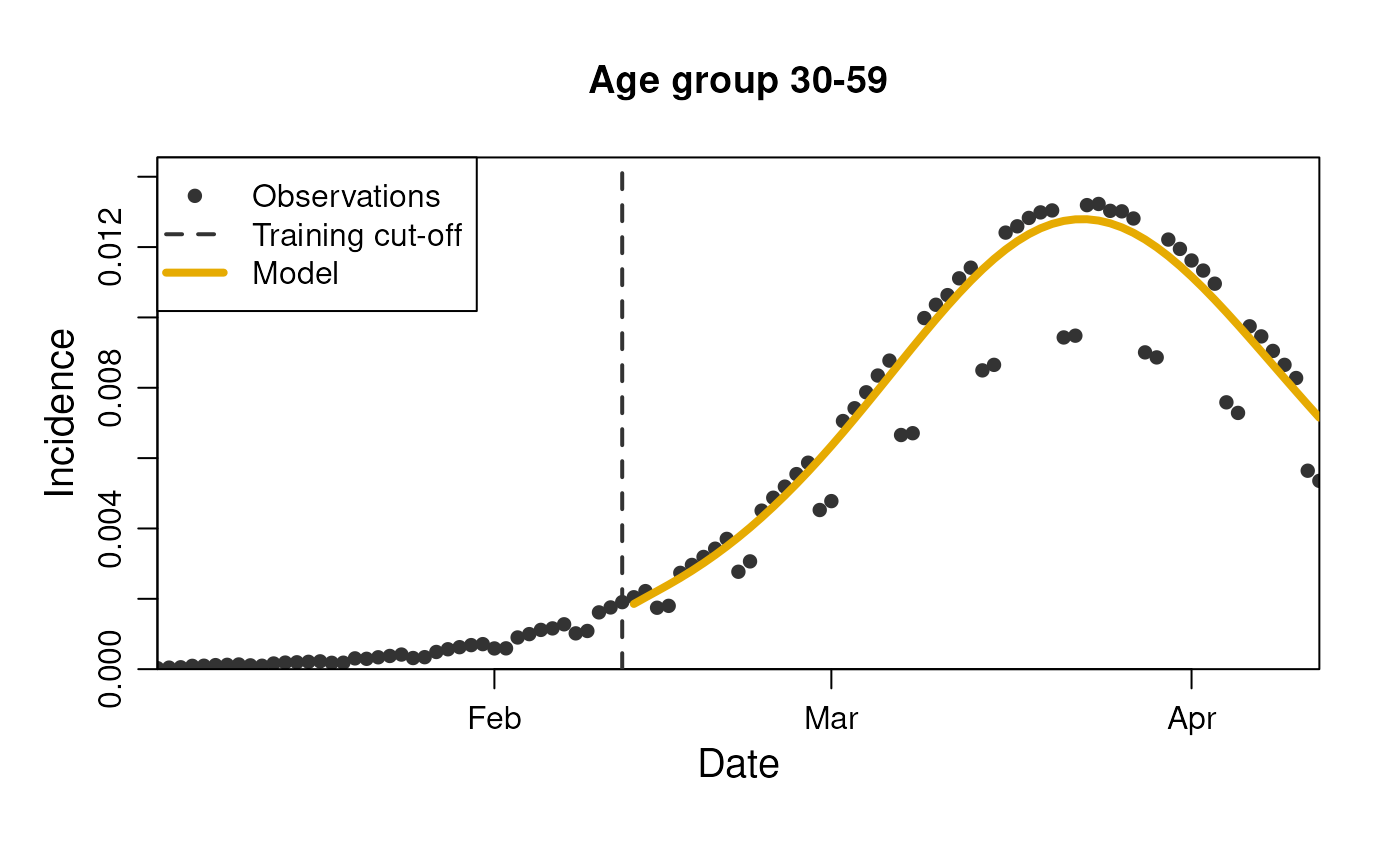
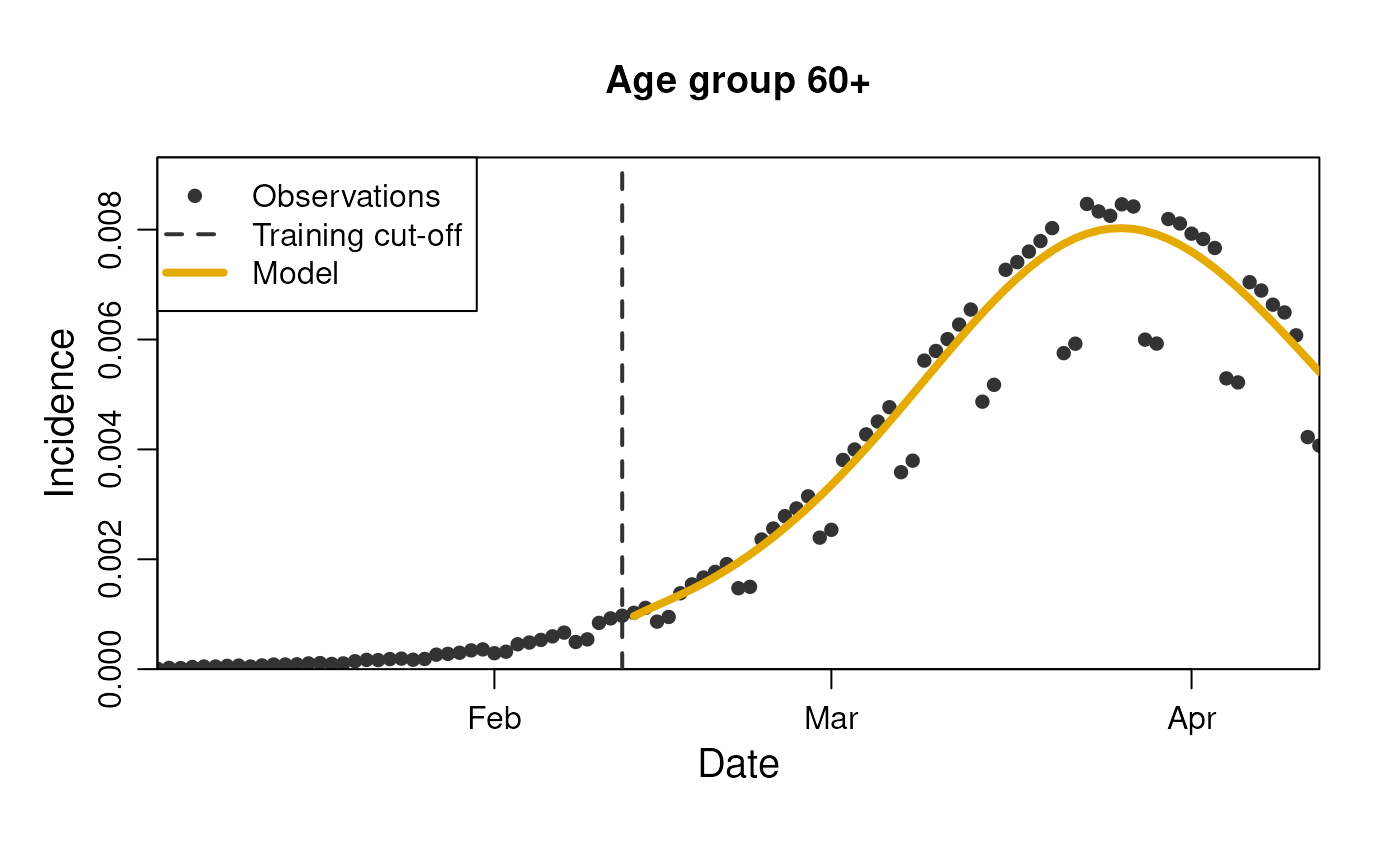
This can be done for all the observables we have mapped in the model.
model$get_results(
observable = "n_infected",
prediction_length = 5
)
#> # A tibble: 5 × 4
#> date n_infected realisation_id weight
#> <date> <dbl> <dbl> <dbl>
#> 1 2020-02-18 11642. 1 1
#> 2 2020-02-19 12360. 1 1
#> 3 2020-02-20 13232. 1 1
#> 4 2020-02-21 14202. 1 1
#> 5 2020-02-22 15243. 1 1
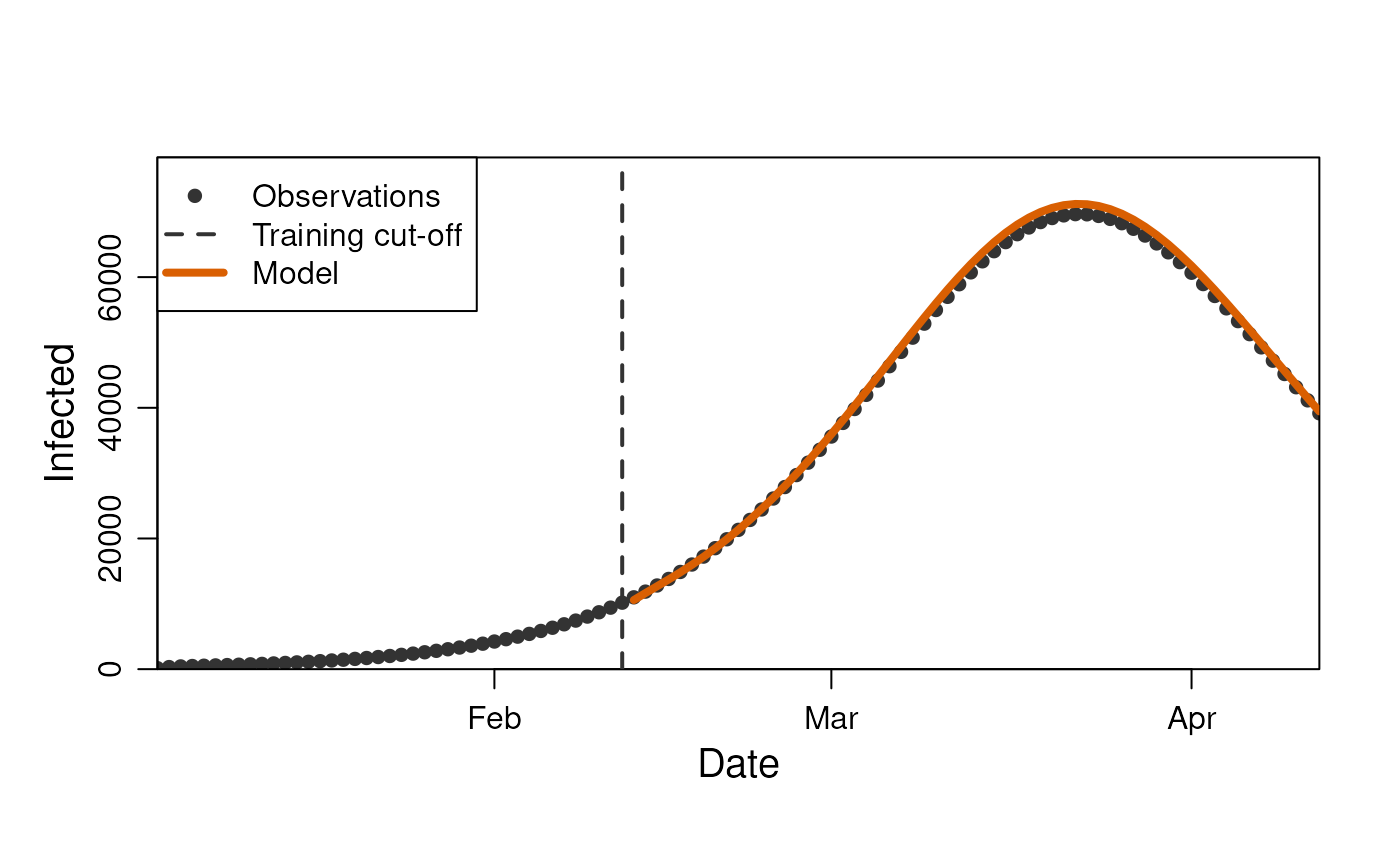
plot(
model,
observable = "n_infected",
prediction_length = 60
)
model$get_results(
observable = "n_infected",
prediction_length = 3,
stratification = rlang::quos(age_group)
)
#> # A tibble: 9 × 5
#> date age_group n_infected realisation_id weight
#> <date> <chr> <dbl> <dbl> <dbl>
#> 1 2020-02-18 00-29 5350. 1 1
#> 2 2020-02-19 00-29 5673. 1 1
#> 3 2020-02-20 00-29 6076. 1 1
#> 4 2020-02-18 30-59 4682. 1 1
#> 5 2020-02-19 30-59 4974. 1 1
#> 6 2020-02-20 30-59 5321. 1 1
#> 7 2020-02-18 60+ 1609. 1 1
#> 8 2020-02-19 60+ 1713. 1 1
#> 9 2020-02-20 60+ 1835. 1 1
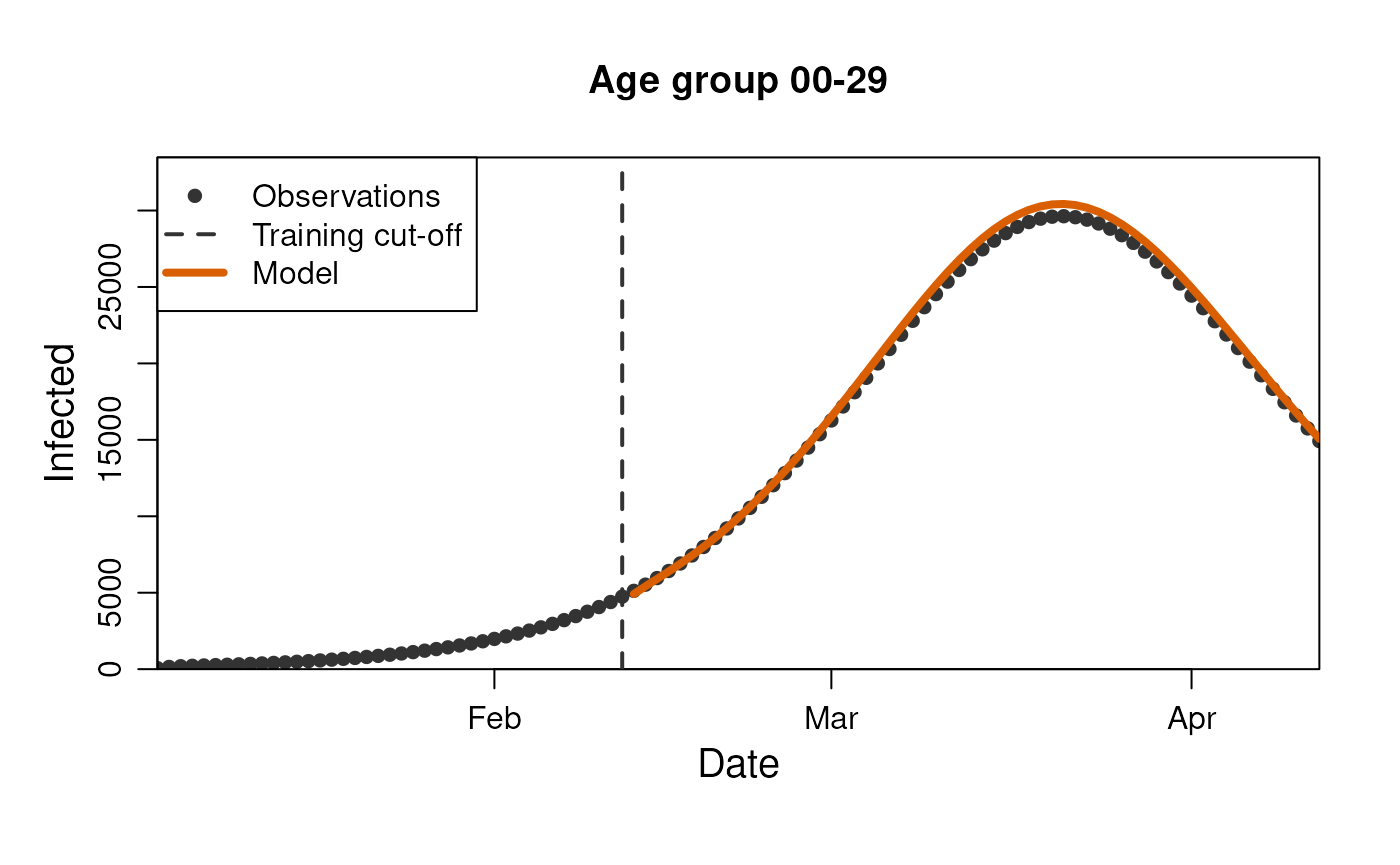
plot(
model,
observable = "n_infected",
prediction_length = 60,
stratification = rlang::quos(age_group)
)
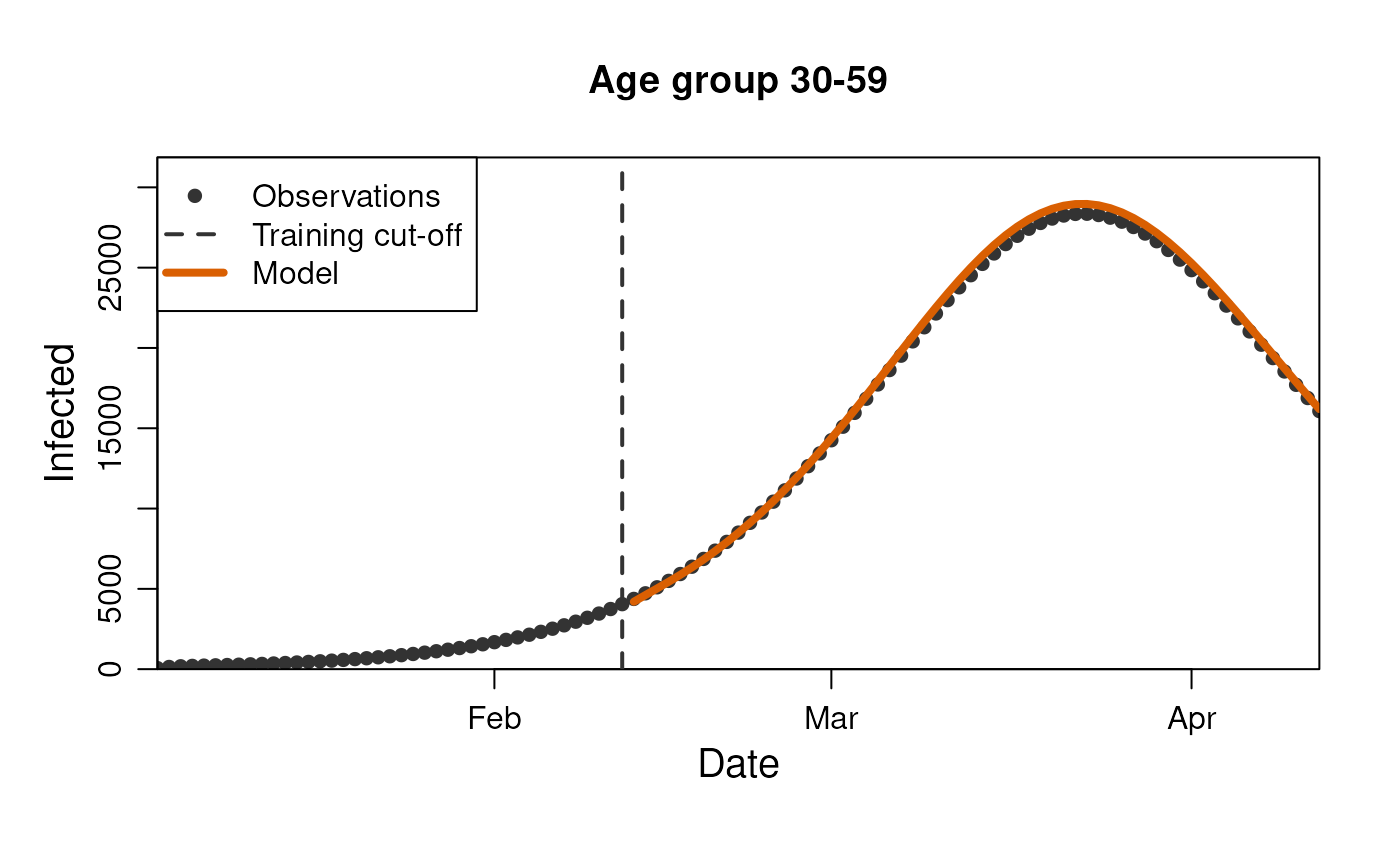
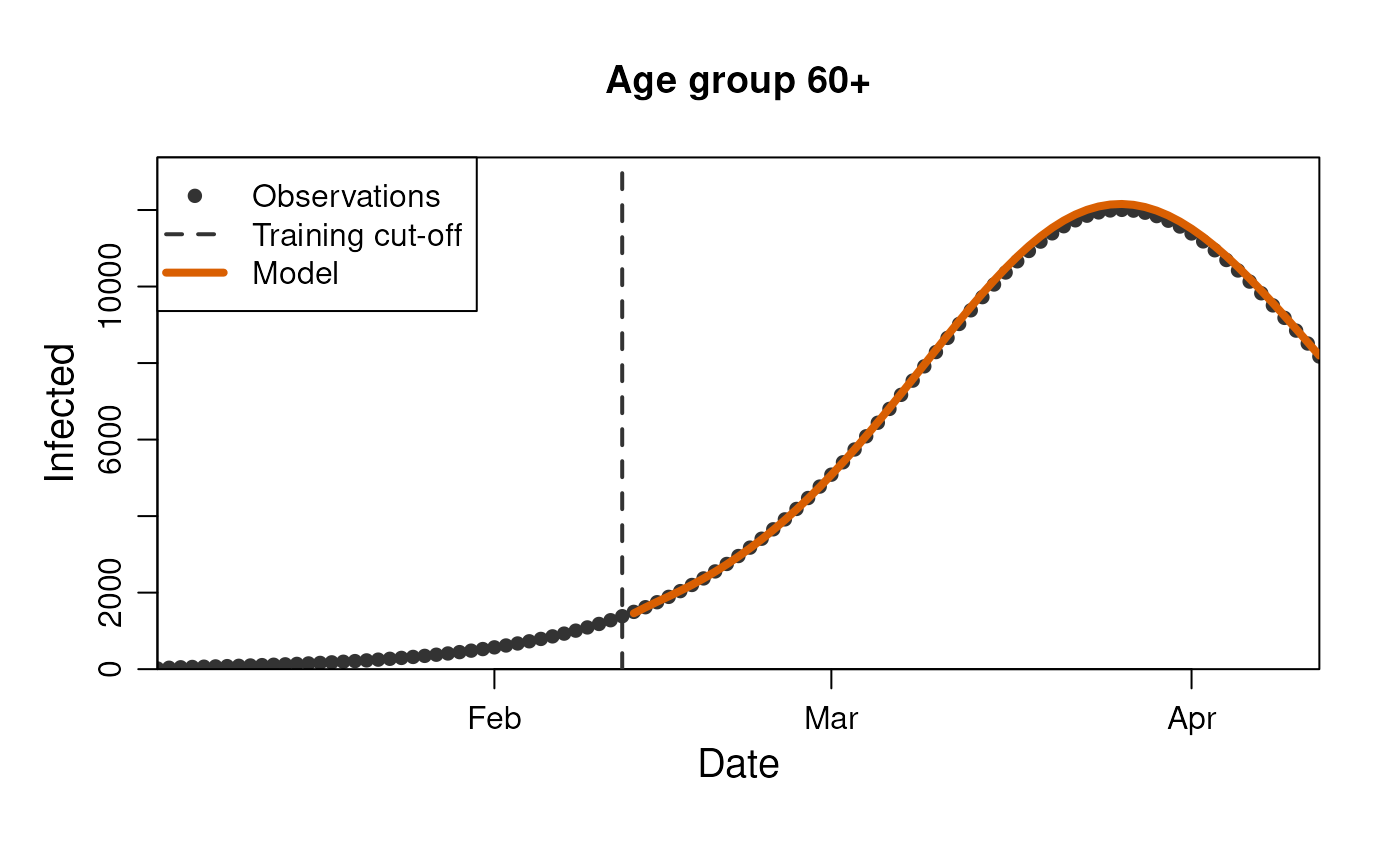
model$get_results(
observable = "n_positive",
prediction_length = 5
)
#> # A tibble: 5 × 4
#> date n_positive realisation_id weight
#> <date> <dbl> <dbl> <dbl>
#> 1 2020-02-18 7567. 1 1
#> 2 2020-02-19 8034. 1 1
#> 3 2020-02-20 8601. 1 1
#> 4 2020-02-21 9232. 1 1
#> 5 2020-02-22 9908. 1 1
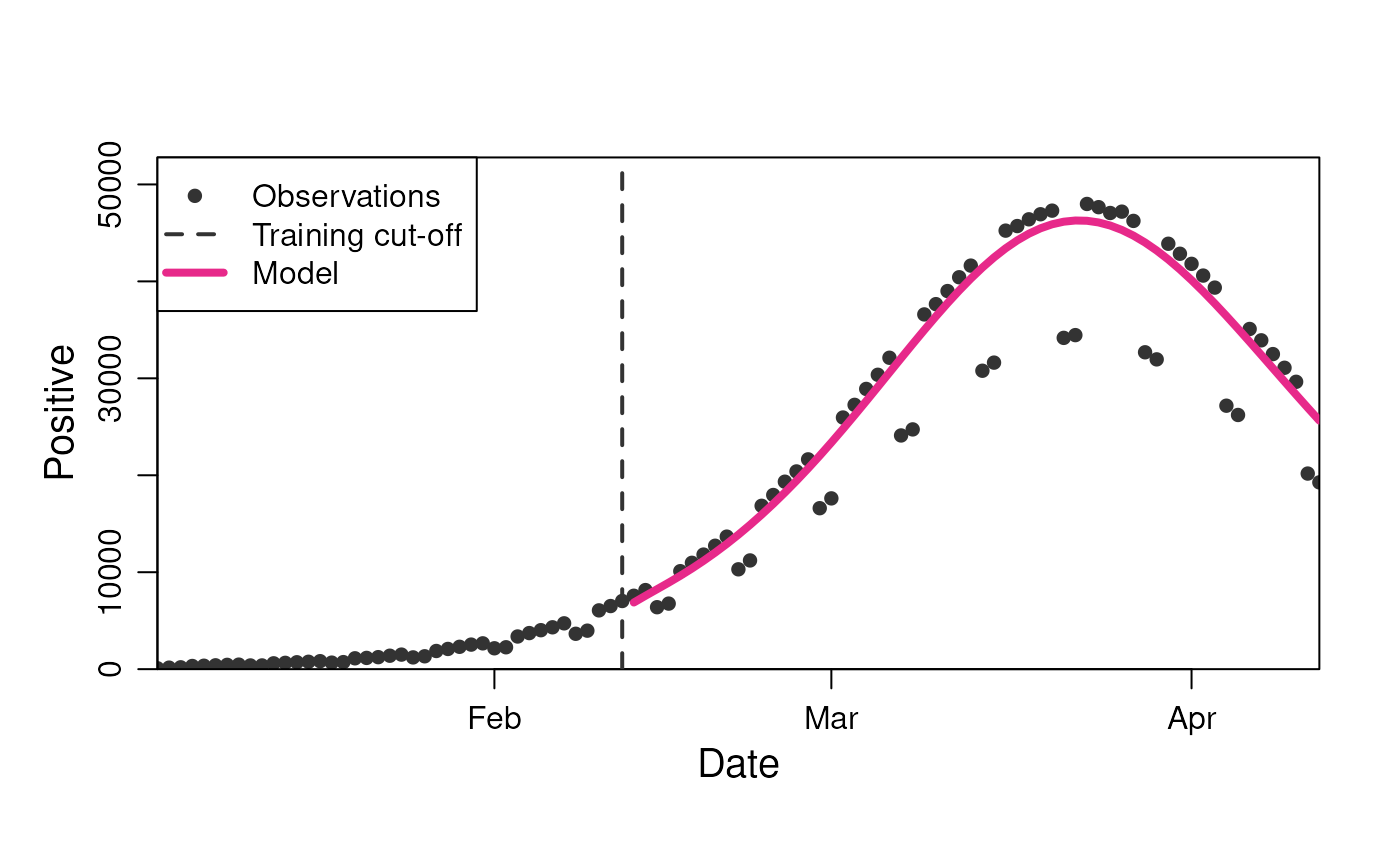
plot(
model,
observable = "n_positive",
prediction_length = 60
)
model$get_results(
observable = "n_positive",
prediction_length = 3,
stratification = rlang::quos(age_group)
)
#> # A tibble: 9 × 5
#> date age_group n_positive realisation_id weight
#> <date> <chr> <dbl> <dbl> <dbl>
#> 1 2020-02-18 00-29 3478. 1 1
#> 2 2020-02-19 00-29 3687. 1 1
#> 3 2020-02-20 00-29 3949. 1 1
#> 4 2020-02-18 30-59 3043. 1 1
#> 5 2020-02-19 30-59 3233. 1 1
#> 6 2020-02-20 30-59 3459. 1 1
#> 7 2020-02-18 60+ 1046. 1 1
#> 8 2020-02-19 60+ 1114. 1 1
#> 9 2020-02-20 60+ 1193. 1 1
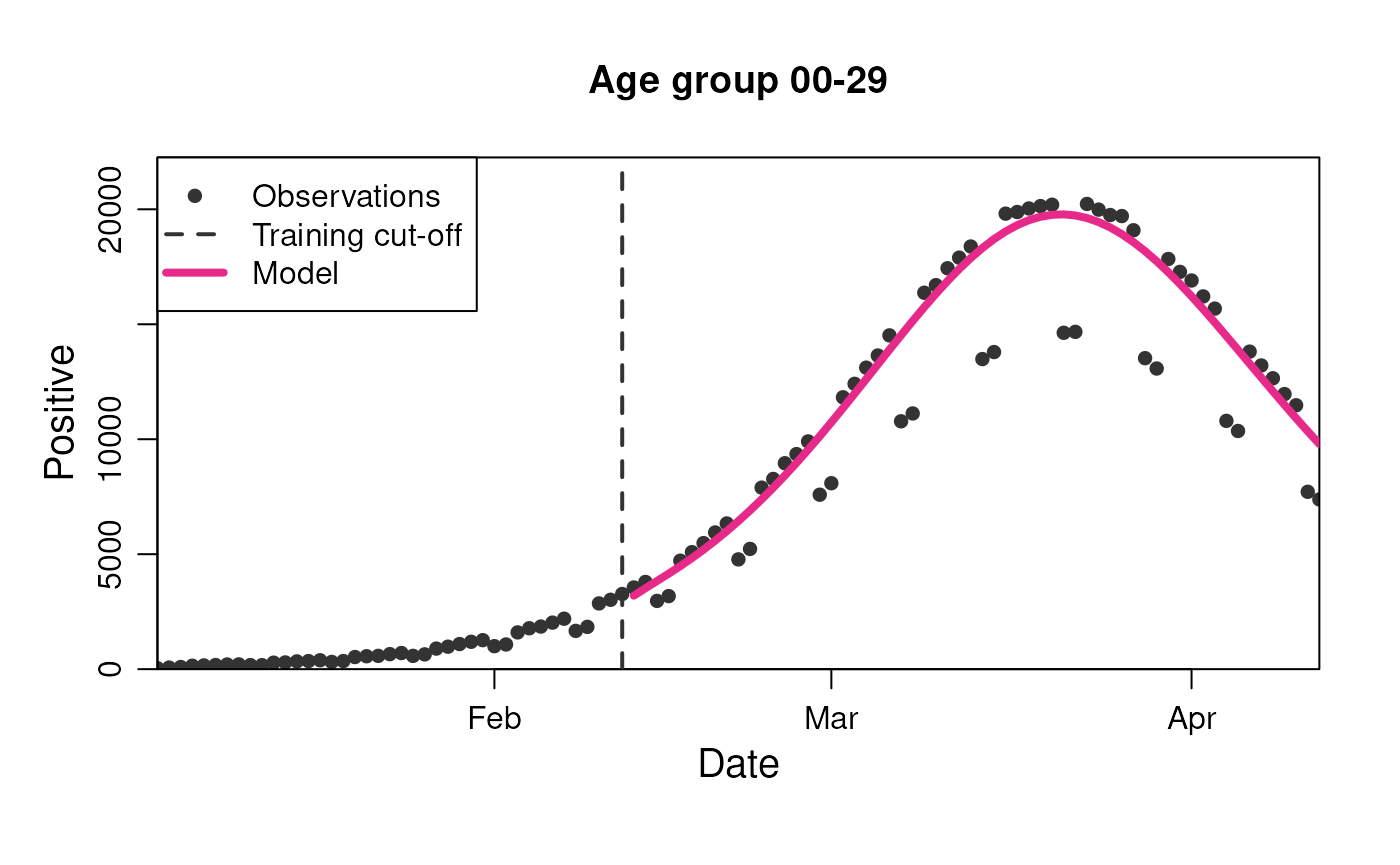
plot(
model,
observable = "n_positive",
prediction_length = 60,
stratification = rlang::quos(age_group)
)
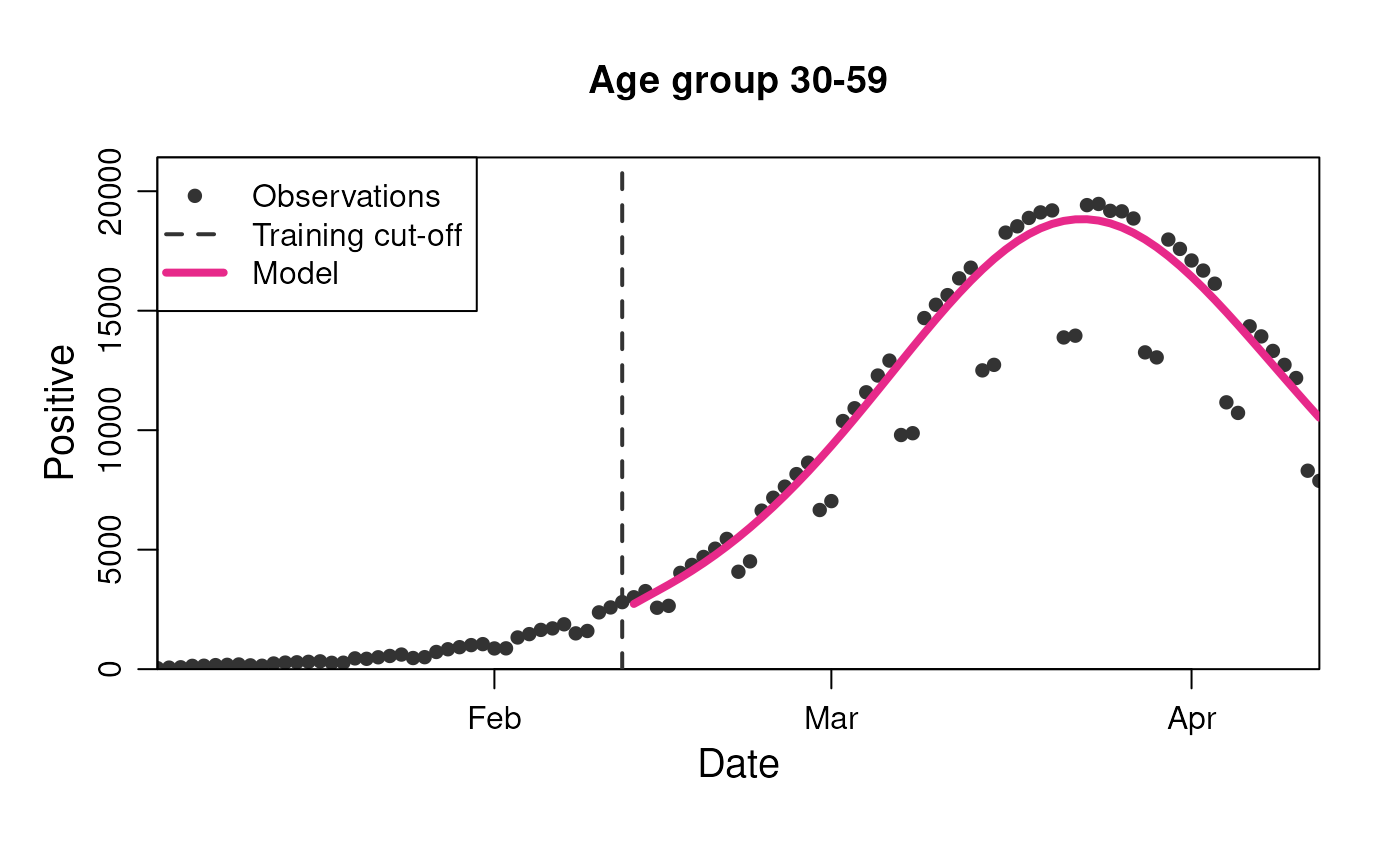
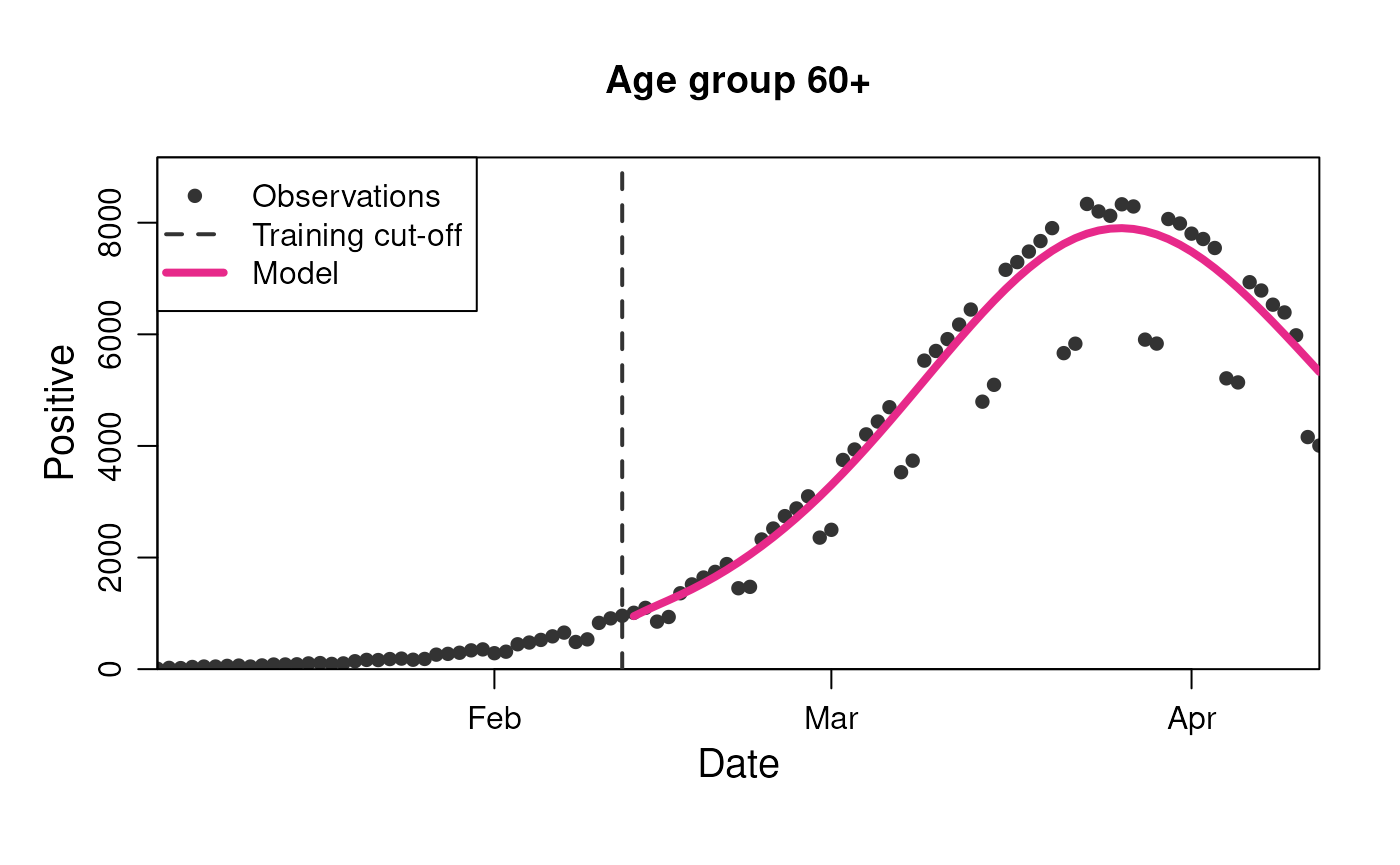
model$get_results(
observable = "n_admission",
prediction_length = 5
)
#> # A tibble: 5 × 4
#> date n_admission realisation_id weight
#> <dbl> <dbl> <dbl> <dbl>
#> 1 18310 167. 1 1
#> 2 18311 169. 1 1
#> 3 18312 184. 1 1
#> 4 18313 200. 1 1
#> 5 18314 217. 1 1
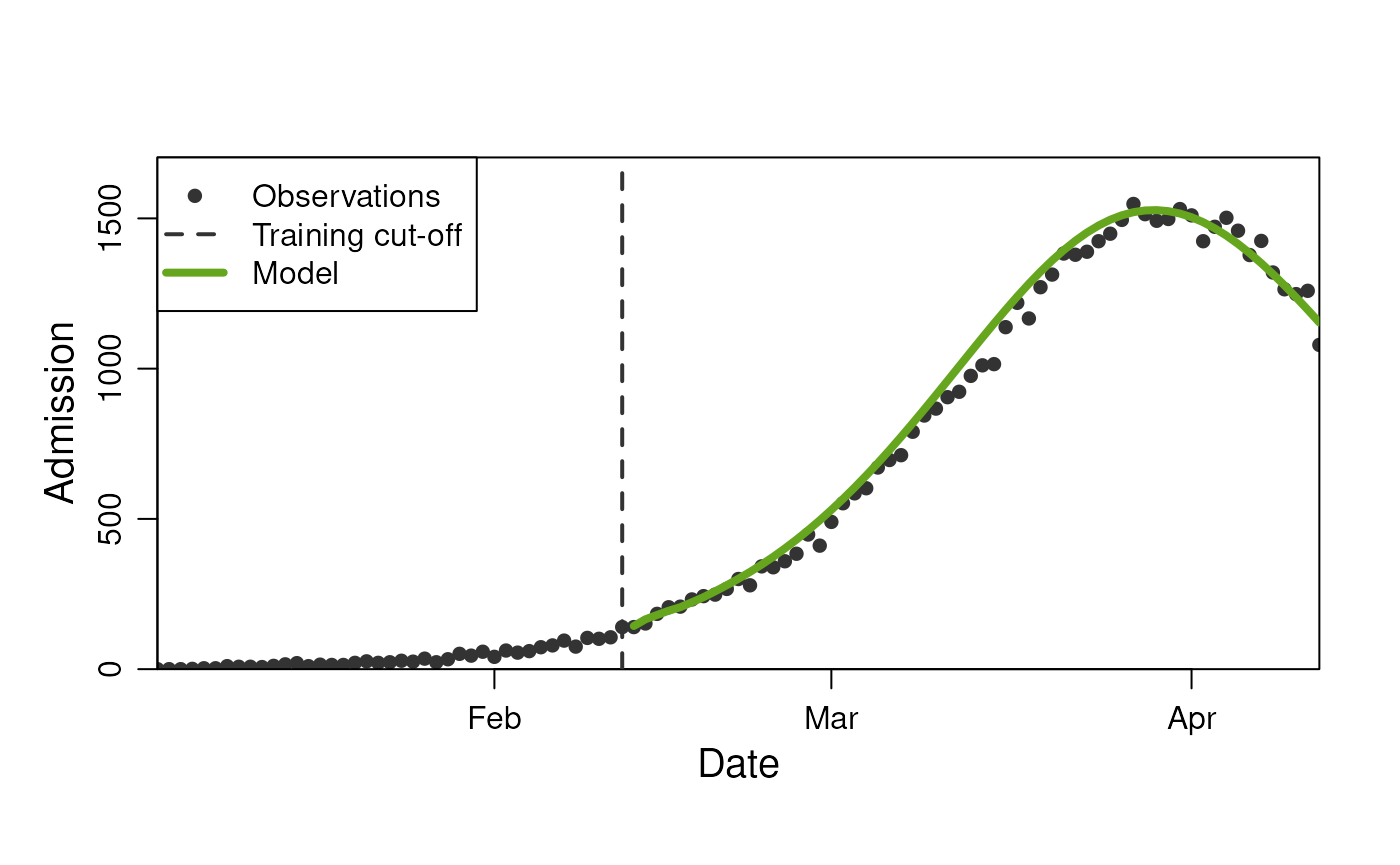
plot(
model,
observable = "n_admission",
prediction_length = 60
)
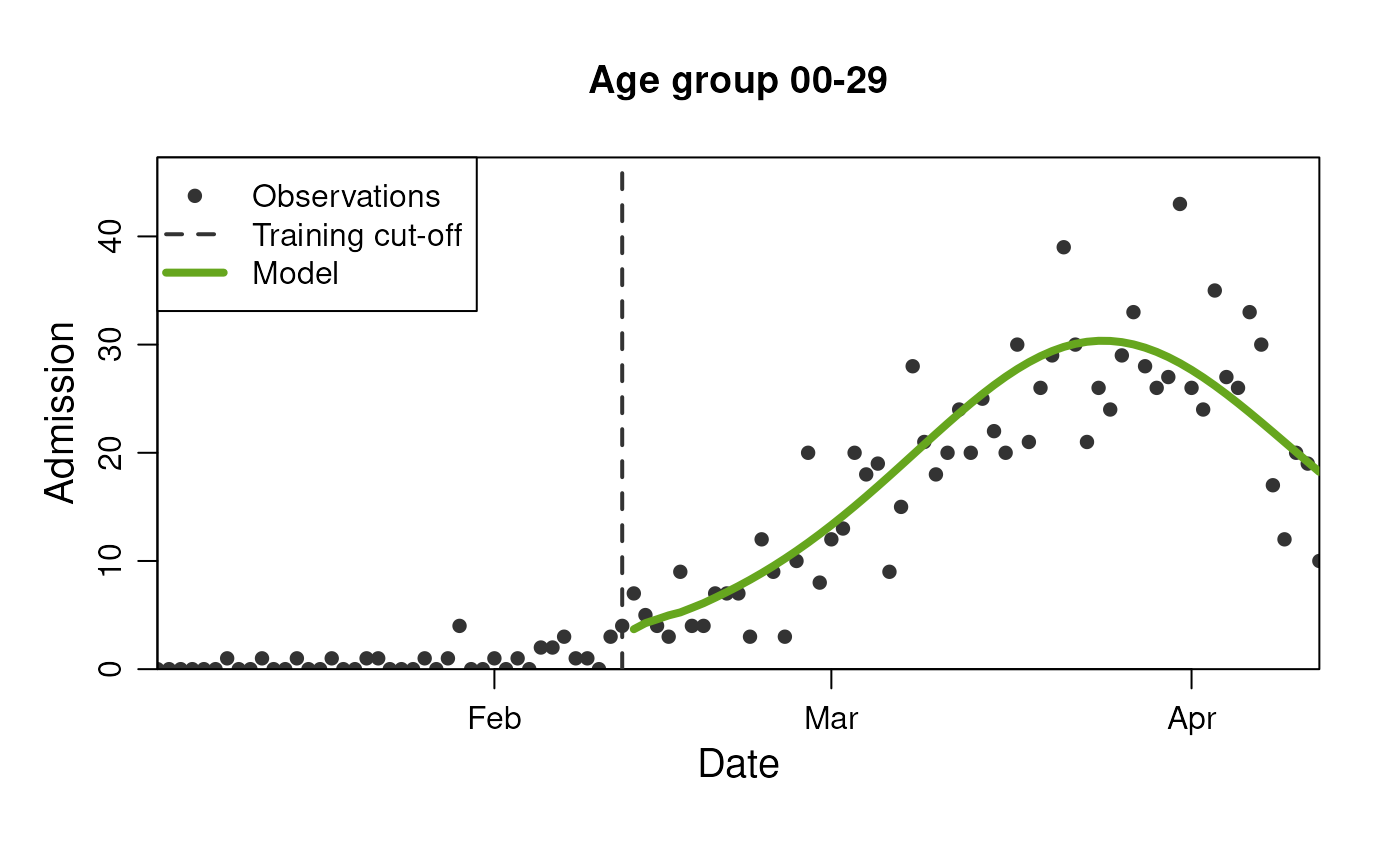
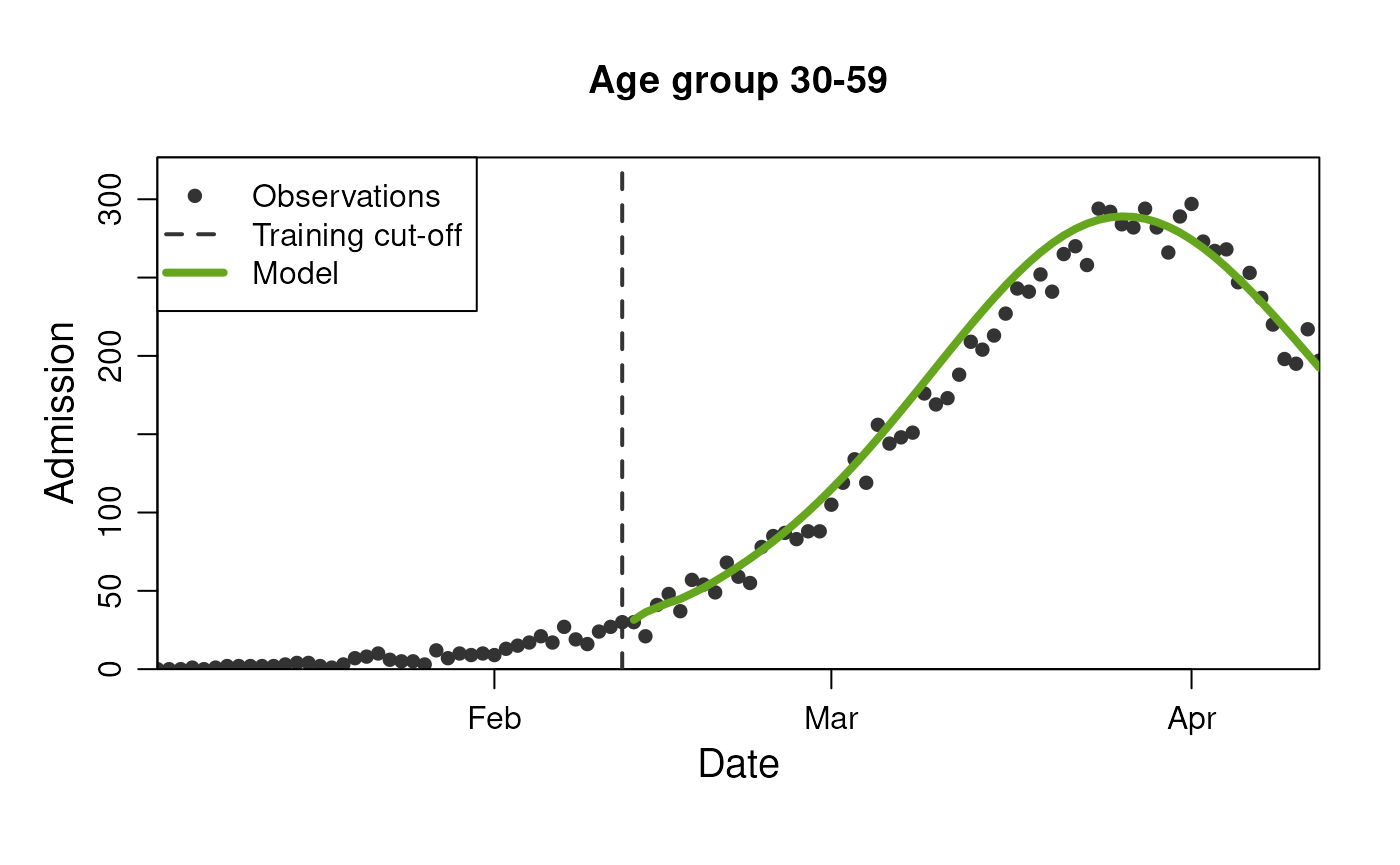
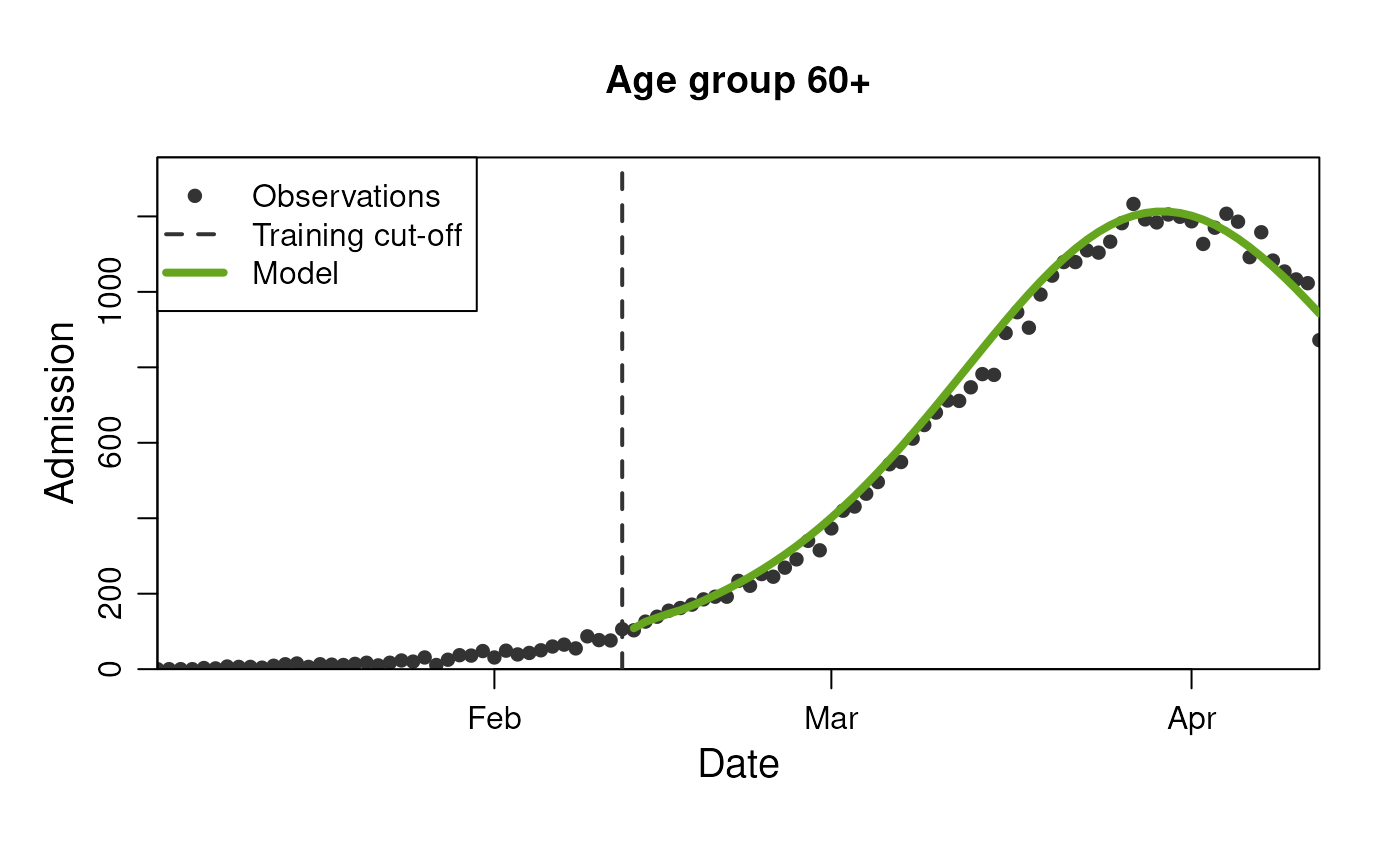
model$get_results(
observable = "n_admission",
prediction_length = 3,
stratification = rlang::quos(age_group)
)
#> # A tibble: 9 × 5
#> date age_group n_admission realisation_id weight
#> <dbl> <chr> <dbl> <dbl> <dbl>
#> 1 18310 00-29 4.38 1 1
#> 2 18311 00-29 4.38 1 1
#> 3 18312 00-29 4.71 1 1
#> 4 18310 30-59 37.2 1 1
#> 5 18311 30-59 37.4 1 1
#> 6 18312 30-59 40.9 1 1
#> 7 18310 60+ 125. 1 1
#> 8 18311 60+ 127. 1 1
#> 9 18312 60+ 139. 1 1
plot(
model,
observable = "n_admission",
prediction_length = 60,
stratification = rlang::quos(age_group)
)